架构
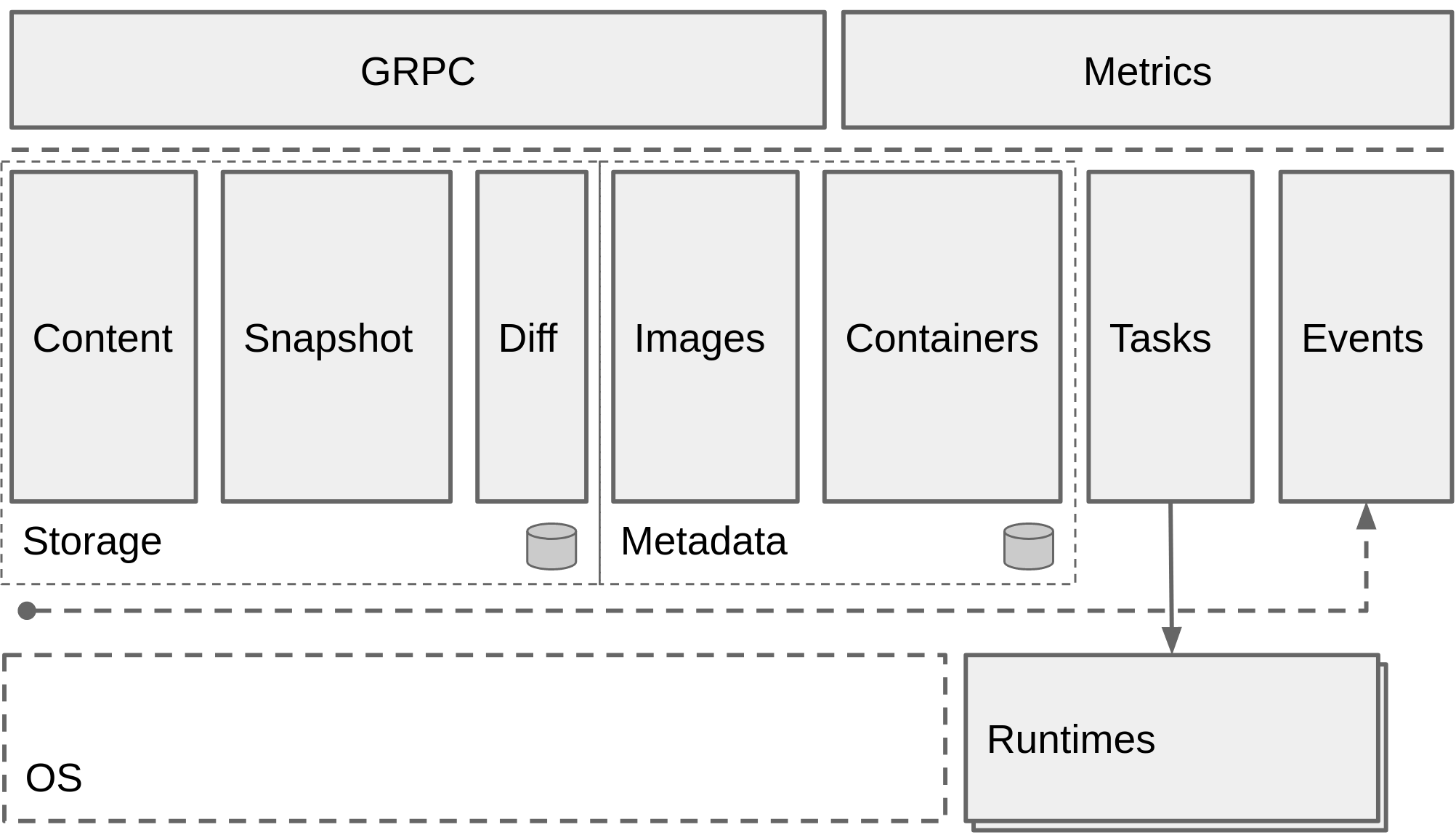
为确保关注点清晰分离,我们将 containerd 的行为单元组织成 组件。这些 组件 大致又组织成 子系统。跨越子系统的 组件 可能被称为 模块。模块 通常提供横切功能,例如持久存储或事件分发。理解这些 组件 及其相互关系是修改和扩展系统的关键。
本文档将介绍非常高层次的交互。有关每个模块的详细信息,请参阅相关设计文档。
该架构的主要目标是协调 bundle 的创建与执行。Bundles 包含配置、元数据和根文件系统数据,并由 runtime 消费。一个 bundle 是运行时容器在磁盘上的表示。Bundles 是可变的,可以传递给其他系统进行修改,或打包分发。实际上,它通常只是文件系统上的一个目录。
注意:虽然这些架构思想对于理解系统很重要,但代码布局可能并不完全反映出相同的架构。应将这些思想作为放置功能与行为以及理解设计背后思路的指导。
子系统
外部用户通过 gRPC API 提供的服务与系统交互。
- Bundle:bundle 服务允许用户从磁盘镜像中提取和打包 bundles。
- Runtime:运行时服务支持对 bundles 的执行,包括运行时容器的创建。
通常,每个子系统会有一个或多个相关的 控制器 组件来实现该子系统的行为。子系统的行为可能通过相应的 服务 导出以供访问。
模块
除了子系统之外,我们还有若干可能跨越子系统边界的组件(称为组件/模块)。主要包括:
- Executor:执行器实现实际的容器运行时。
- Supervisor:监督器监控并报告容器状态。
- Metadata:在图数据库中存储元数据。用于保存对镜像和 bundle 的任何持久引用。写入数据库的数据将由组件之间协调的 schema 管理,以便访问任意数据。其它功能还包括对磁盘资源进行垃圾回收的钩子。
- Content:提供对内容可寻址存储(content-addressable storage)的访问。所有不可变内容都存放在此处,并以内容哈希为键。
- Snapshot:管理容器镜像的文件系统快照。这类似于当前 Docker 中的 graphdriver。镜像层会被解包到快照中。
- Events:支持事件的收集与消费,以提供一致的事件驱动行为与审计。事件可以被重放到各个 模块。
- Metrics:每个组件都会导出若干指标,可通过指标 API 访问。(我们可能会将其提升为一个子系统。)
客户端侧组件
为提高灵活性,部分组件在客户端实现:
- Distribution:用于拉取与推送镜像的功能。
数据流
如上所述,bundle 的概念是 containerd 的核心。下面的图示说明了 bundle 创建时的数据流。
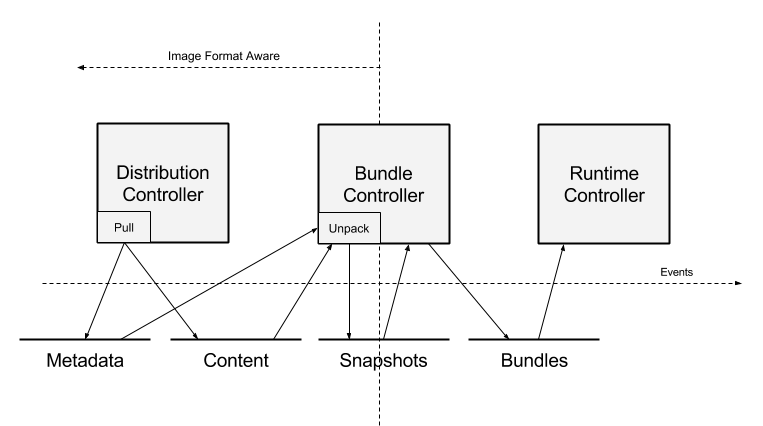
以拉取镜像为示例说明流程:
- 指示分发层(Distribution)拉取特定镜像。分发层将镜像内容放入内容存储(content store)。镜像名称和根清单(root manifest)指针会在元数据存储中登记。
- 镜像拉取完成后,用户可以指示 bundle 控制器将镜像解包为一个 bundle。控制器从内容存储读取数据,将镜像的各层解包到 snapshot 组件中。
- 当容器根文件系统(rootfs)的快照准备就绪后,bundle 控制器可以使用镜像清单和配置来准备执行配置(execution configuration)。其中一部分工作是将来自 snapshot 模块的挂载项加入执行配置。
- 准备好的 bundle 随后会交由运行时子系统(runtime)执行。运行时读取 bundle 的配置以创建正在运行的容器。
数据流
过去,容器系统常常将拉取容器镜像的复杂性隐藏起来,许多细节与复杂流程对用户不可见。本文档旨在揭示这些复杂性,并从 containerd 用户的角度详细描述一次 "pull" 操作会是什么样子。我们在该工作流中以 bundle 作为目标对象,并从该对象往回推来描述完整过程。在此上下文中,我们既会描述拉取镜像,也会描述如何从该镜像创建 bundle。
在 containerd 中,我们将 "pull" 重新定义为包含此前容器引擎所涵盖的同一组步骤。在这个模型中,镜像定义了一组可用于创建 bundle 的资源。并不存在一种叫做 "image" 的特定格式或对象。pull 的目标是解析组成镜像的资源集合——这种分离在流程中提供了生命周期的切入点。
containerd 将提供一个在客户端执行的完整 "pull" 的参考实现,但这并不意味着会存在单一的 "pull" API 调用。
下面给出一个粗略的数据流图示以及相关组件。
尽管流程在图中从左到右进行撰写,但本文档是从右向左来编写的。通过倒推该流程,我们可以最好地理解 containerd 所采用的方法。
运行一个容器
对于 containerd,我们通常希望检索一个 bundle。这是运行时在磁盘上的容器布局,包含运行容器所需的文件系统和配置。
一般来说,我们可以把它表示为下面的目录结构:
config.json
rootfs/在此语境下,config.json 的具体内容并不重要,但为清晰起见,它可能是 runc 的配置或用于设置运行容器的 containerd 特定配置文件。rootfs 是 containerd 用来搭建运行时容器文件系统的目录。
尽管 containerd 没有镜像(image)的概念,我们仍然可以根据映射到 containerd 的镜像来构建上述结构。基于此,我们可以说运行一个容器所需的步骤为:
- 将容器镜像中的配置转换为 containerd 运行时的目标格式。
- 从容器镜像重建根文件系统(root filesystem)。我们可以把它解包到 bundle 的
rootfs中,也可以将其作为一组挂载项传入容器配置。
以上定义了我们的工作框架。换句话说,我们希望通过创建 bundle 的这两个组成部分来创建一个 bundle。
创建一个 Bundle
既然我们已经定义了运行容器(即 bundle)所需的内容,就需要创建一个 bundle。
假设我们执行:
ctr run ubuntu这并不会去拉取镜像。它仅仅使用名称创建一个 bundle。分解成步骤,该过程如下:
- 在元数据存储(metadata store)中查找该镜像对应的 digest。
- 在内容存储(content store)中解析 manifest。
- 在 snapshot 子系统中解析层(layer)快照。
- 将配置转换为目标 bundle 格式。
- 为容器的 rootfs 创建运行时快照,包括对挂载点的解析。
- 运行容器。
由此,我们可以理解拉取(pull)镜像所需的资源:
- 在元数据存储中有一个条目,名称指向某个特定的 digest。
- manifest 必须已存在于内容存储中。
- 顺序应用各层后得到的结果必须以 snapshot 的形式可用。
解包(Unpacking)层
无论该过程是由 pull 驱动还是由 run 驱动,其思想都很简单。对于每一层,将该层的变更应用到前一层的 snapshot 上。结果应当根据 OCI 所定义的 chain id 来存储。
拉取(Pull)镜像
基于以上定义,拉取镜像变为以下步骤:
- 获取镜像的 manifest,验证并存储它。
- 获取镜像 manifest 中的每一层,验证并存储它们。
- 将 manifest 的 digest 在所提供的名称下登记存储。
注意:此处我们暂不讨论如何使用名称解析到特定位置(registry 等)。那会另写一篇文档来说明。
容器生命周期
虽然 containerd 是一个提供管理多个容器的守护进程(daemon),但容器本身并不依赖于 containerd 的生命周期。每个容器都有一个 shim,作为容器进程的直接父进程,负责上报退出状态并持有容器的标准输入/输出(STDIO)。这也使得即便 containerd 崩溃,容器的所有功能仍能被恢复。
containerd
该守护进程提供用于管理多个容器的 API。它可在必要时在进程内处理锁定,以协调子系统之间的任务。尽管守护进程会 fork 出运行容器所需的进程(例如 shim 与 runc),但这些进程会被重新归属为系统的 init(即成为 init 的子进程)。
shim
每个容器都有自己的 shim,作为该容器进程的直接父进程。shim 负责保持容器的 IO 和/或 pty 主端(pty master)打开、为 containerd 写入容器的退出状态,并在容器进程退出时进行回收(reap)。由于 shim 持有容器的 pty 主端,它还提供用于调整终端尺寸的 API。
总体而言,容器的生命周期并不与 containerd 守护进程绑定。守护进程只是为多个容器提供管理 API,而每个容器的生命周期由对应的 shim 管理(每个容器对应一个 shim)。
快照(Snapshots)
从一开始,Docker 容器长期以来就是基于一种称为 layers(层)的快照方法构建的。Layers 提供了派生文件系统、进行修改然后将变更集保存为新层的能力。
历史上,这些机制被紧密集成在 Docker 守护进程中,作为名为 graphdriver 的组件。graphdriver 使得在多种操作系统上运行 docker 守护进程成为可能,同时仍能在提交和分发镜像更改时保持大致相似的快照语义。
graphdriver 深度参与镜像的导入与导出,包括管理层关系和容器运行时的文件系统。graphdriver 的行为会影响镜像格式的传输方式。
在本文档中,我们提出一种更灵活的管理层的模型。该模型侧重于为基础快照功能提供 API,而不与镜像结构及其标识紧密耦合。最小化的 API 在不牺牲能力的前提下简化了行为。这使得驱动实现的表面更小,保证不同实现间的行为更一致。
与 graphdriver 的概念不同,Snapshotter 并不关心镜像或容器。用户仅需准备并提交目录。我们也避免将 graph driver 与用于表示变更集的 tar 格式耦合。
最好的方面是,我们可以通过重构现有的 graphdrivers 达到该模型,从而最小化新增代码和庞大测试的需求。
范围
过去,graphdriver 组件在 Docker 中提供了大量功能,包括序列化、哈希计算、解包、打包和挂载。
Snapshotter 只会提供面向挂载的快照访问,并带有最小的元数据。序列化、哈希、解包、打包和(额外的)挂载功能不包含在该设计内,优选在 graphdrivers 之间使用通用实现,而非各自专用实现。由于接口提供对变更集的直接访问,这对性能的影响较小。
架构
Snapshotter 提供用于分配、快照和挂载基于层的抽象文件系统的 API。该模型通过构建具有父子关系的一组目录来工作,这些目录称为 Snapshots。
Snapshot 表示一种文件系统状态。每个 snapshot 都有一个父级,其中空父级由空字符串表示。可以在父级与其 snapshot 之间取差异以创建经典的层(layer)。
通过生命周期可以最好地理解 snapshots。Active(活动)快照总是由对一个 Committed(已提交)快照(包括空快照)调用 Prepare 或 View 创建。Committed 快照总是由对一个 Active 快照调用 Commit 创建。活动快照永远不会变成已提交快照,反之亦然。所有快照都可以被移除。
在挂载一个 Active 快照后,可以对该快照进行修改。提交(commit)操作会创建一个 Committed 快照。已提交快照将继承活动快照的父级。已提交快照随后可以被用作父级。活动快照永远不能被用作父级。
下图演示了快照之间的关系:
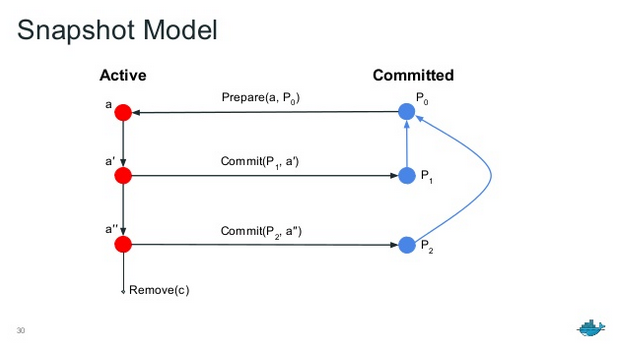
在该图中,可以看到活动快照 a 通过以已提交快照 P0 为父调用 Prepare 创建。修改后,a 变成 a',通过调用 Commit 创建了已提交快照 P1。a' 可以进一步修改为 a'',再次调用 Commit 可以创建第二个已提交快照 P2。注意这里 P2 的父级是 P0 而不是 P1。
操作
Snapshots 的体现由 Mount 对象和用于不透明数据存储的用户定义目录来协助实现。创建新的活动快照时,调用方提供一个称为 key 的标识符。此操作返回一组挂载点(mounts),如果将它们挂载,则在挂载路径上会有完全准备好的快照。我们称此操作为 prepare。
一旦快照被 prepared 并且挂载,调用方就可以向快照写入新数据。根据应用的不同,用户可能希望保留这些更改,也可能不想保留。
对于只读视图,可以使用 view 操作。与 prepare 类似,view 会返回一组挂载点,如果将它们挂载则在挂载路径上会有完全准备好的快照。
如果用户希望保留更改,则使用 commit 操作。commit 操作接收表示活动快照的 key 标识符以及一个 name 标识符。成功后会创建一个 committed 快照,当通过该 name 引用时,可用作新 active 快照的父级。
如果用户希望放弃活动快照中的更改,可调用 remove 操作来释放与该快照相关的任何资源。prepare 或 view 返回的挂载点应在调用该方法前先卸载。
如果用户希望丢弃已提交的快照,也可使用 remove 操作,但必须先删除其所有子项后才能继续。
有关详细使用信息,请参阅 GoDoc。
图形元数据(Graph metadata)
当快照被导入到容器系统时,会形成一个快照及其父关系的"图"。对该图的查询必须作为受支持的操作。
快照如何工作
为具体化 Snapshots 术语,我们将从导入层的角度演示 Snapshotter 的使用。我们将使用 Go API 来表示该过程。
导入一层(Importing a Layer)
要导入一层,我们只需让 Snapshotter 提供一组挂载以便目标位置能够捕获变更集。我们先获取层 tar 文件的路径并创建一个临时位置用于解包:
layerPath, tmpDir := getLayerPath(), mkTmpDir() // just a path to layer tar file.我们首先使用 Snapshotter 对一个新快照事务调用 Prepare,使用一个 key 并以空父级 "" 下降:
mounts, err := snapshotter.Prepare(key, "")
if err != nil { ... }Snapshotter.Prepare 会返回一组挂载点,key 标识该活动快照。将其挂载到临时位置:
if err := mount.All(mounts, tmpDir); err != nil { ... }一旦执行了挂载,我们的临时位置就准备好捕获差异了。实际上,这类似于文件系统事务。下一步是解包该层。我们有一个特殊函数 unpackLayer,它会将层的内容应用到目标位置并计算解包后层的 DiffID(这是 docker 实现的要求):
layer, err := os.Open(layerPath)
if err != nil { ... }
digest, err := unpackLayer(tmpLocation, layer) // unpack into layer location
if err != nil { ... }完成上述操作后,我们应该得到一个表示该层内容的文件系统。稳健的实现应当验证 digest 是否与期望的 DiffID 匹配。完成后,我们卸载挂载点:
unmount(mounts) // optional, for now现在我们已验证并解包层,接着将活动快照提交到一个 name。在此示例中,我们仅使用层摘要(digest),但在实际中,这很可能是 ChainID:
if err := snapshotter.Commit(digest.String(), key); err != nil { ... }现在,我们在 Snapshotter 中有了一个可通过提交时提供的 digest 访问的层。提交快照后,可以使用如下方式移除活动快照:
snapshotter.Remove(key)导入下一层
使新层依赖于上述层的过程与上文相同,不同之处在于在调用 Snapshotter.Prepare 时提供父级 parent,假定 tmpLocation 是干净的:
mounts, err := snapshotter.Prepare(tmpLocation, parentDigest)然后像之前一样挂载、应用并提交。新的快照将基于之前快照的内容。
运行容器
要运行容器,我们只需将已提交的镜像快照作为父级传入 Snapshotter.Prepare。挂载后,准备好的路径可以直接用作容器的文件系统:
mounts, err := snapshotter.Prepare(containerKey, imageRootFSChainID)返回的挂载点可以直接传递给容器运行时。如果想从该文件系统创建新镜像,则调用 Snapshotter.Commit:
if err := snapshotter.Commit(newImageSnapshot, containerKey); err != nil { ... }或者,对于大多数容器运行场景,会调用 Snapshotter.Remove 来通知 Snapshotter 放弃这些更改。
挂载(Mounts)
挂载是 containerd 中的主要交互机制。过去的容器系统通常会有若干各自独立的组件分别执行挂载,导致在协调大规模挂载栈时生命周期管理复杂且容易出错。
在 containerd 中,我们打算将挂载系统调用限制在容器运行时组件内,选择让各个组件生成挂载的序列化表示。这样可以确保挂载作为一个整体执行,并作为一个整体卸载。
从架构角度看,组件负责产生挂载(mounts),运行时执行器负责消费这些挂载。
更富想象力的用例包括能够在不创建运行时的情况下虚拟化来自各个组件的一系列挂载,这将有助于测试和辅助组件(satellite components)的实现。
结构
Mount 类型遵循传统 mount 系统调用的结构:
| 字段 | 类型 | 说明 |
|---|---|---|
| Type | string | 挂载的具体类型,通常与操作系统相关 |
| Target | string | 挂载目标的预期文件系统路径 |
| Source | string | 发起挂载的对象,通常是设备或另一个文件系统路径 |
| Options | []string | 要与挂载一起应用的零个或多个选项,可能是以 = 分隔的键值对 |
我们可能希望进一步参数化以支持带有各种辅助程序(例如 mount.fuse)的挂载,但这暂不在本文件范围内。